MongoDB数据库索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。本文将详细介绍MongoDB数据库索引
引入
索引能够提高查询效率,如何体现呢?接下来使用性能分析函数explain()来进行分析说明
首先,插入10万条数据

接着,不创建索引,来寻找time范围在100和200之间的文档

由图中所知,totalDocsExamined值为100000,表示查找了100000个文档;nReturned值为101,表示返回了101个文档;executionTimeMillis值为39,表示花费了39ms
下面,我们在time字段上建立索引
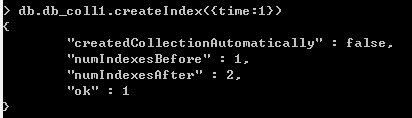
再次,寻找time范围在100和200之间的文档
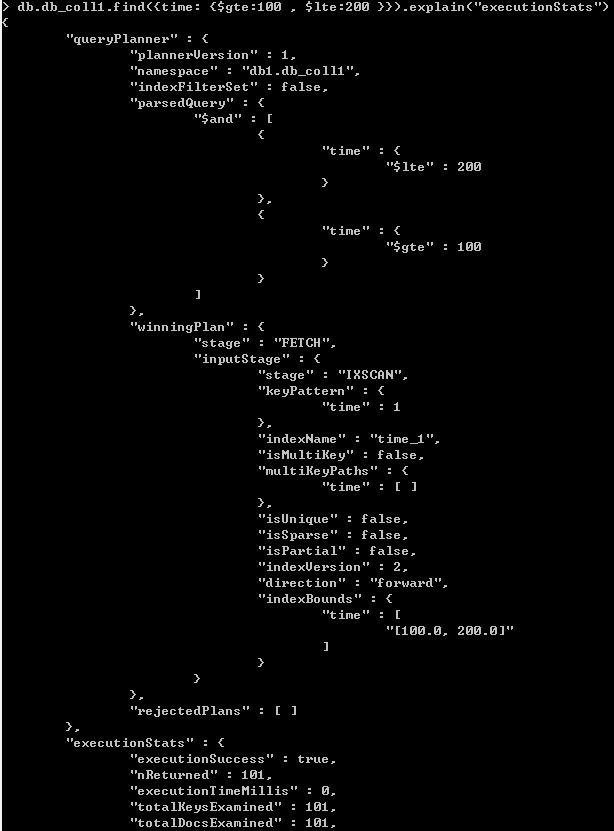
由图可知,totalDocsExamined和nReturned值都是101,executionTimeMillis值为0,相当于从101个文档中,找到了101个文档,查找的速度趋近于0。由此可见,使用索引极大地提升了查询速度
概述
索引是特殊的数据结构,以易于遍历的形式存储数据集的一小部分。 索引存储特定字段或一组字段的值,按照索引中指定的字段值排序
使用索引,可以加快索引相关的查询,也相应地带来一些坏处
1、增加磁盘空间的消耗。在索引比较多的情况下,索引文件所占据的空间有可能超过数据本身
2、在写入数据或更新数据时,对索引的维护一般是写之外的另一条逻辑,一定程度上,会降低写入性能
但是,为了查询的高效,这些影响是值得的。有很多情况下,系统的性能下降,与不合理的索引创建有关。所以,合理的创建索引,可以减少索引带来的不好的影响
索引设置
【getIndexes()】
使用getIndexes()方法来查询索引
db.collection_name.getIndexes()
由下图可知,有"_id"和"time"两个索引

【createIndex()】
db.COLLECTION_NAME.createIndex({KEY:1})语法中Key值为要创建的索引字段,1为指定按升序创建索引,如果想按降序来创建索引指定为-1即可
当然,也可以创建多个索引字段
db.COLLECTION_NAME.createIndex({k1:1,k2:1})在MongoDB3.0版本之前,使用的是ensureIndex()方法,现在ensureIndex()方法依然可以使用,只是createIndex()方法的别名
如果文档较多,创建索引需要耗费一定的时间。如果系统负载较重,且有很多已经存在的文档,不能直接使用这个命令进行创建,需要在使用数据库之前,就将索引创建完毕。否则,严重影响数据库的性能
[注意]索引可以重复创建,如果对已经存在的索引再次创建,会直接返回成功
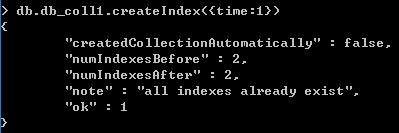
createIndex() 接收可选参数,可选参数列表如下:
Parameter Type Description background Boolean 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,默认值为false unique Boolean 建立的索引是否唯一。指定为true创建唯一索引。默认值为false name string 索引的名称。如果未指定,MongoDB通过连接索引的字段名和排序顺序生成一个索引名称 dropDups Boolean 在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false sparse Boolean 对文档中不存在的字段数据不启用索引;如果设置为true,索引字段中不会查询出不包含对应字段的文档。默认值为false v index version 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本 weights document 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重 expireAfterSeconds integer 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间 default_language string 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 language_override string 对于文本索引,该参数指定了包含在文档中的字段名,默认值为language
db.db_coll1.createIndex({time:1},{background:true})【dropIndex()】
使用db.collection_name.dropIndex({key:1})方法可以删除指定索引
db.collection_name.dropIndex({key:1})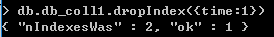
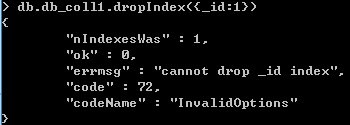
[注意]_id索引无法被删除
除了使用键值对来删除索引,还可以使用其name值来删除索引
如下所示,{time:1}的name值为"time_1",使用db.db_coll1.dropIndex("time_1")也可以删除索引

【dropIndexes()】
使用db.collection_name.dropIndexes()方法可以删除所有索引
db.collection_name.dropIndexes()
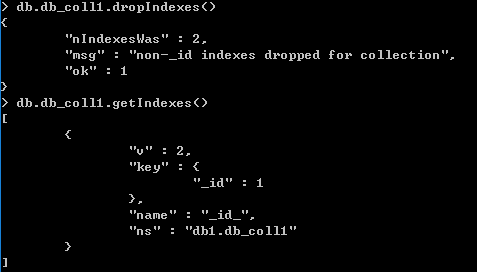
索引属性
【TTL】
过期索引又称为TTL索引,是一种特殊类型的单字段索引,主要用于当满足某个特定时间之后自动删除相应的文档。也就是说集合中的文档有一定的有效期,超过有效期的文档就会失效,会被移除。也即是数据会过期。过期的数据无需保留,这种情形适用于如机器生成的事件数据,日志和会话信息等等
同样地,过期索引使用createIndex()方法来创建,但它支持第二个参数expireAfterSeconds,用来指定多少秒过期或者包含过期日期值的数组
db.eventlog.createIndex( { x: 1 }, { expireAfterSeconds: 3600 } )以下示例中,在60s后,会删除time文档
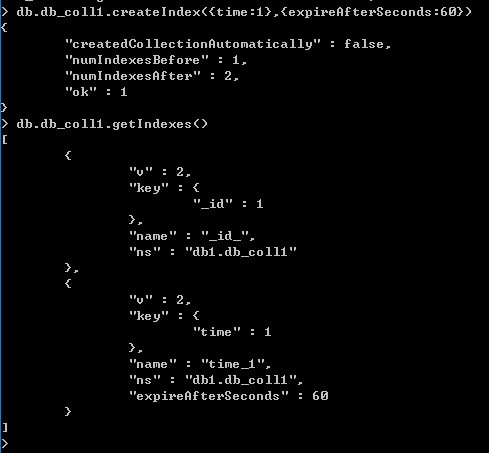
使用过期索引,有以下几点注意事项
1、存储在过期索引字段的值必须是指定的时间类型。必须是ISODate或者ISODate数组,不能使用时间戳,否则不能被自动删除
以下示例中time设置了ISODate类型的值,该值到60s后会被自动删除
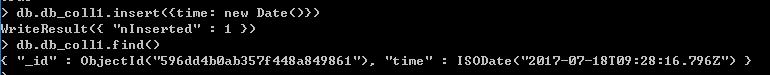
以下示例中,time设置了时间戳,该值到60s后无法被删除
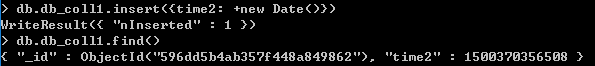
2、如果指定了ISODate时间数组,则按照最小的时间进行删除
3、过期索引不能是复合索引
4、删除时间是不精确的。删除过程是由后台程序每60s跑一次,而且删除也需要一些时间,存在误差。所以,如果设置的到期时间与当前时间的间隔小于60s,则文档最少也要60s才能被删除
【唯一性】
索引的属性可以具有唯一性,即唯一索引,只要设置索引属性中的unique为true即可,默认为false。唯一索引用于确保索引字段不存储重复的值,即强制索引字段的唯一性。缺省情况下,mongodb的_id字段在创建集合的时候会自动创建一个唯一索引
db.collection_name.createIndex({},{unique:true})如下图所示,在默认情况下,不是唯一索引
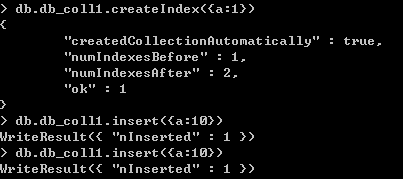
在设置unique:true后,不能插入重复的值
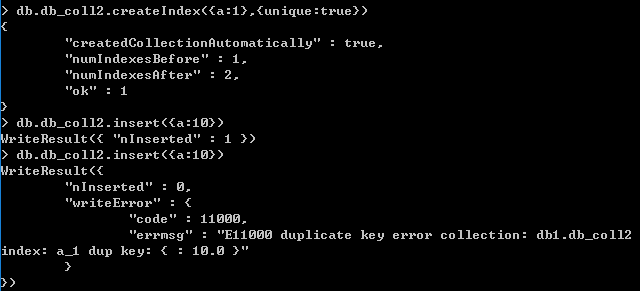
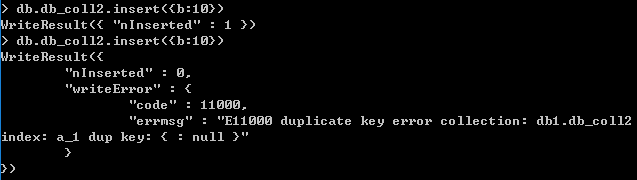
常见错误
如下图所示,设置的a字段为唯一索引,b字段也无法输入重复的值。这是因为设置a字段为唯一索引,插入数据b:10,相当于a:null,再插入b:10时,相当于又插入了a:null。而a:null和a:null是重复的,而a字段是唯一索引,无法重复。所以,无法插入重复的b:10
【稀疏性】
索引的属性可以具有稀疏性,即稀疏索引,只要设置索引属性中的sparse为true即可,默认为false
db.collection_name.createIndex({},{sparse:true})稀疏性的不同代表了MongoDB在处理索引中存在但文档中不存在的字段的两种不同的方法
稀疏索引,也称为间隙索引就是创建索引的索引列在某些文档上列不存在,导致索引存在间隙。
假设,在一个集合中,创建了x字段上的索引。但是,插入的文档中并不包含x字段。在默认情况下,MongoDB依然会为这条不存在的字段创建索引。如果把这条索引创建为稀疏索引,则这条索引将不会被使用
如果数据集合中很多文档在创建索引的字段上并没有值,使用稀疏索引可以减少磁盘占用,且提高插入速度
$exits
使用稀疏索引时,可能会带来一些隐患。MongoDB提供了一种$exits操作符,$exits表示字段是否存在
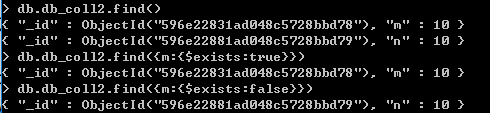
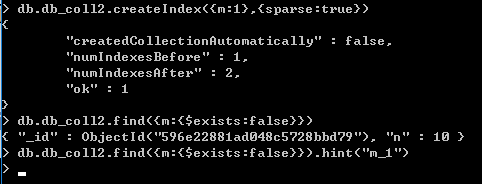
由下图所示,创建了{m:1}的稀疏索引,使用find()方法查找不存在m字段的文档时,结果出现了。是因为,MongoDB并没有使用稀疏索引来查询
如果使用hint()方法强制使用稀疏索引来查找索引上存在而文档中不存在的字段,则没有结果。再次说明稀疏索引不能用来查找索引上存在,但文档里不存在的字段
索引种类
MongoDB支持基于集合文档上任意列创建索引。缺省情况下,所有的文档的_id列上都存在一个索引。基于业务的需要,可以基于一些重要的查询和操作来创建一些额外的索引。这些索引可以是单列,也可是多列(复合索引),多键索引,地理空间索引,全文索引等
MongoDB支持6种索引,包括
1、_id索引
2、单键索引
3、多键索引
4、复合索引
5、全文索引
6、地理位置索引
【_id索引】
_id索引是绝大多数集合默认建立的索引,对于每个插入的数据,MongDB都会自动生成一条唯一的_id字段
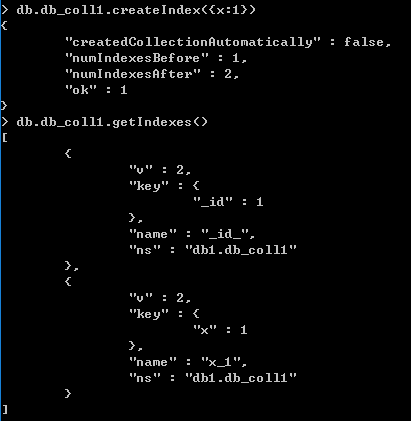
由下图所示,在未插入任何索引之前,已经存在_id索引

【单键索引】
单键索引是最普通的索引,与_id索引不同,单键索引不会自动创建
比如,一条记录,形式为{x:1,y:2,z:3},在x字段上建立索引,之后就可以使用x为条件进行查询
【多键索引】
在MongoDB中可以基于数组来创建索引。mongodb为数组每一个元素创建索引值。多键索引支持数组字段的高效查询。多键索引能够基于字符串,数字数组以及嵌套文档进行创建
多键索引与单键索引创建形式相同,区别在于字段的值。单键索引的值为单一的值,如一个字符串、数字或日期。多键索引的值具有多个记录,如一个数组
如果mongoDB中插入数组类型的多键数据,索引是自动建立的,无需刻意指定。但是,使用getIndexes()方法并没有多键索引,除非显式地创建多键索引
【复合索引】
MongoDB支持复合索引,即将多个键组合到一起创建索引。该方式称为复合索引,或者也叫组合索引,该方式能够满足多键值匹配查询使用索引的情形。其次复合索引在使用的时候,也可以通过前缀法来使用索引
[注意]任意复合索引字段不能超过31个
比如,插入{x:1,y:2,z:3}的记录,当需要按照x与y的值进行查询时,就需要创建x与y的复合索引。接着,就可以使用x和y作为条件进行查询
db.db_coll1.createIndex({x:1,y:1})
db.db_coll1.createIndex({x:-1,y:1})
db.db_coll1.createIndex({x:-1,y:-1})
db.db_coll1.createIndex({x:1,y:-1})
db.db_coll1.createIndex({y:1,x:1})
db.db_coll1.createIndex({y:-1,x:1})
db.db_coll1.createIndex({y:-1,x:-1})
db.db_coll1.createIndex({y:1,x:-1})复合索引创建时按升序或降序来指定其排列方式。对于单键索引,其顺序并不是特别重要,因为MongoDB可以在任一方向遍历索引。对于复合索引,按何种方式排序能够决定该索引在查询中能否被使用到
x与y的复合索引共包括以上8种情况,x和y的先后次序不同,升序或降序不同 ,都会产生不同的索引。而查询优化器,会使用我们建立的这些索引来创建查询方案,最终选择出最优的索引来查询数据
索引前缀指的是复合索引的子集
假如存在如下索引
{ "item": 1, "location": 1, "stock": 1 }那存在下列索引前缀
{ item: 1 }
{ item: 1, location: 1 }在MongoDB中,下列查询过滤条件情形中,索引将会被使用到
item字段 item字段 + location字段 item字段 + location字段 + stock字段 item字段 + stock字段(尽管索引被使用,但不高效)
以下过滤条件查询情形,索引将不会被使用到
location字段 stock字段 location + stock字段
全文索引
【创建】
全文索引也叫做文本索引,常见于搜索框中。我们在搜索框中输入关键词,比如 "HTML",不仅标题中带有"HTML"的文章会被搜索出来,而且文章中存在"HTML"的文章也会被搜索出来
为了索引一个存储字符串或者字符串数组的键,需要在创建选项中包含这个键并指定为 "text" ,如下:
db.reviews.createIndex( { comments: "text" } )如果需要在多个字段上创建全文索引,则可以复合索引
db.reviews.createIndex(
{
subject: "text",
comments: "text"
}
)如果需要对所有字段创建全文索引,则需要使用$xx标识
db.collection_name.createIndex( { "$**": "text" } )[注意]一个集合最多只能创建 一个 文本 索引
【使用】
如果使用全文索引进行搜索,则需要使用如下格式
db.collection_name.find({$text:{$search: '...'}})假设使用如下的数据结构来存储一个完整的文章,author存储作者,title存储标题,article存储文章内容
{author:"",title:"",article:""}现在来添加一些数据,并对所有字段创建全文索引
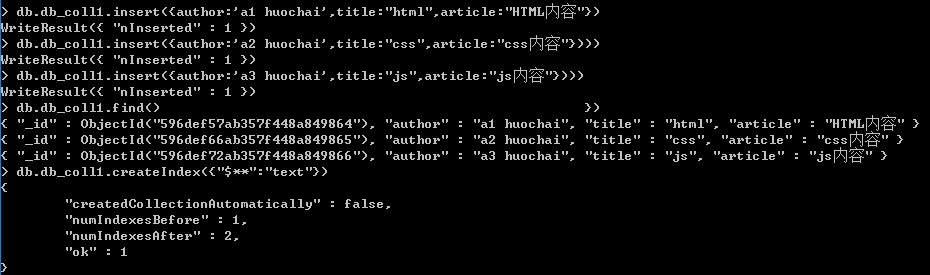
下面来搜索'huochai',可搜索到3条记录
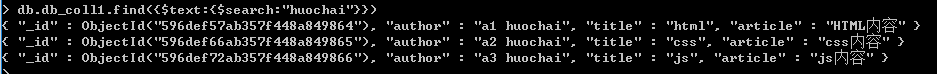
如果搜索'a2',则只能搜索到第2条记录
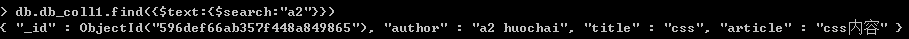
如果搜索'a1 a2 a3',则相当于或的关系,a1 或 a2 或 a3,可以搜索到3条记录
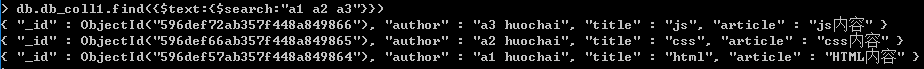
如果搜索'huochai -css',相当于查找包含'huochai',但不包含'css'的记录,包括第1和第3条
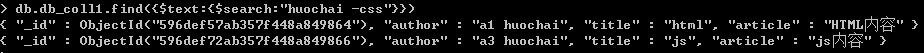
如果要搜索且关系,比如同时包含huochai和css的记录,则需要在内部添加引号," \"huochai\" \"css\" "
[注意]只支持双引号
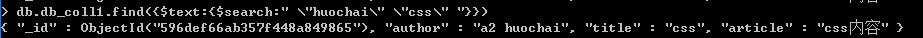
【相似度】
全文索引有一个相似度的概念,表示全文索引的搜索条件与记录的内容有多么相似
在find()方法的第二个参数中,score是一个数字,该数字越大,表示相似度越高
db.collection_name.find({$text:{$search: '...'}},{score:{$meta:"textScore"}})现在,再插入一条内容,作者为'huochai'
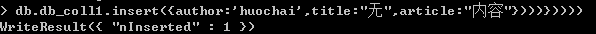
然后开始搜索'huochai',并带有相似度

下面使用相似度排序,相似度高的排在前面
sort({score:{$meta:"textScore"}})
【限制】
1、每次查询,只能指定一个$text查询
2、$text查询不能出现在$nor查询中
3、查询中如果包含了$text,hint()将不再起作用
4、只能对整个单词查询,不能对单词的截取部分查询。类似地,中文做全文查询的时候,只能查询一段话中有空格的该字或者词
地理位置索引
一般地,地理位置索引可以实现诸如按距离排序的餐馆、在某区域内的店铺筛选等
可以将一些点的位置存储在MongoDB中,创建地理位置索引索引后,可以按照位置来查找其他点。地理位置索引可以分为两种:一种是2d索引,用于存储和查找平面上的点;另一种是2dsphere索引,用于存储和查找球面上的点
查找方式一般有两种:一种是查找距离某个点一定范围内的点;另一种是查找包含在某区域内的点
【2D索引】
2D索引的创建方式如下
db.<collection>.createIndex( { <location field> : "2d" , <additional field> : <value> } , { <index-specification options> } )options包括如下参数
{ min : <lower bound> , max : <upper bound> , bits : <bit precision> }
在mongodb中使用经纬度表示位置,[经度, 纬度]。经度范围在[-180,180],纬度范围在[-90,90]
[注意]默认边界允许插入大于90或小于-90的不合理纬度值的文档。而对于这样不合理的点的地理查询,数据库行为是不可预知的。所以,尽量避免插入超出范围的维度值
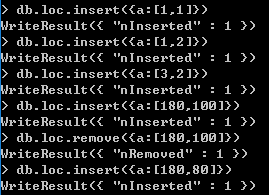
2D索引的查询方式有三种,包括$near、$geoNear、$geoWithin
一种是使用$near查询,即查询距离某个点最近的点,默认返回100个
db.<collection>.find( { <location field> :{ $near : [ <x> , <y> ] } } )
$maxDistance可以设置离当前点最远的距离
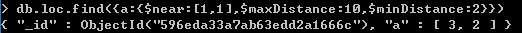
$minDistance可以设置离当前点最近的距离
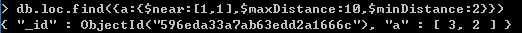
另一种是使用$geoNear查询,$geoNear使用runCommand命令进行使用
db.runCommand({geoNear:<collection_name>,near:[x,y],minDistance:..,maxDistance:..,num:...})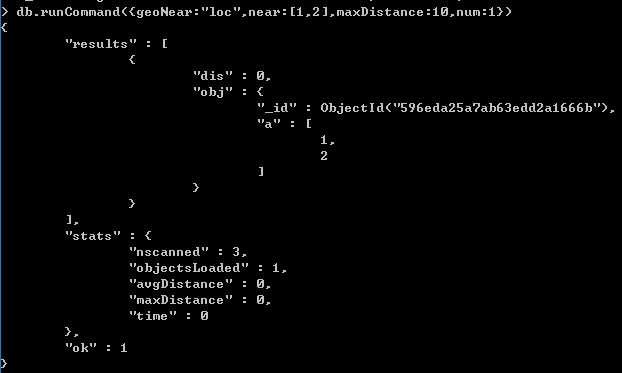
另一种是使用$geoWithin查询,即查询某个形状内的点
在mongodb中,有三种形状,包括矩形、圆形和多边形,使用方法如下
db.<collection>.find( { <location field> :{ $geoWithin :{ $box|$polygon|$center : <coordinates>} } } )第一种是矩形,使用$box表示
{$box:[[x1,y1],[x2,y2]]}

第二种是圆形,使用$center表示
{$center:[[<x1>,<y1>],r]}
第三种是多边形,使用$polygon表示
{$polygon:[[<x1>,<y1>],[<x2>,<y2>],[<x3>,<y3>],...]}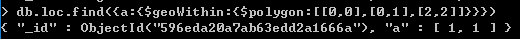
【2dsphere索引】
2dsphere索引的创建方式如下
db.collection_name.createIndex({a:"2dsphere"})位置表示方式不再是简单的经纬度,而是一种GeoJSON的表示方式,用来描述一个点、一条直线、多边形等形状,格式如下
{type:"",coordinates:[<coordinates>]}