使用nodeJS实现前端项目自动化
一般地,我们使用构建工具来完成项目的自动化操作。本文主要介绍如何使用nodeJS来实现简单的项目结构构建和文件合并
项目构建
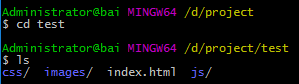
假设,最终实现的项目名称为'test',结构如下图所示

那么,首先需要先设置一个JSON对象来保存要创建的目录结构
var projectData = {
'name' : 'test',
'fileData' : [
{
'name' : 'css',
'type' : 'dir'
},
{
'name' : 'js',
'type' : 'dir'
},
{
'name' : 'images',
'type' : 'dir'
},
{
'name' : 'index.html',
'type' : 'file',
'content' : '<html>\n\t<head>\n\t\t<title>title</title>\n\t</head>\n\t<body>\n\t\t<h1>Hello</h1>\n\t</body>\n</html>',
}
]
};目录结构的创建逻辑如下
var fs = require('fs');
if ( projectData.name ) {
fs.mkdirSync(projectData.name);
var fileData = projectData.fileData;
if ( fileData && fileData.forEach ) {
fileData.forEach(function(f) {
f.path = projectData.name + '/' + f.name;
f.content = f.content || '';
switch (f.type) {
case 'dir':
fs.mkdirSync(f.path);
break;
case 'file':
fs.writeFileSync(f.path, f.content);
break;
default :
break;
}
});
}
}
文件合并
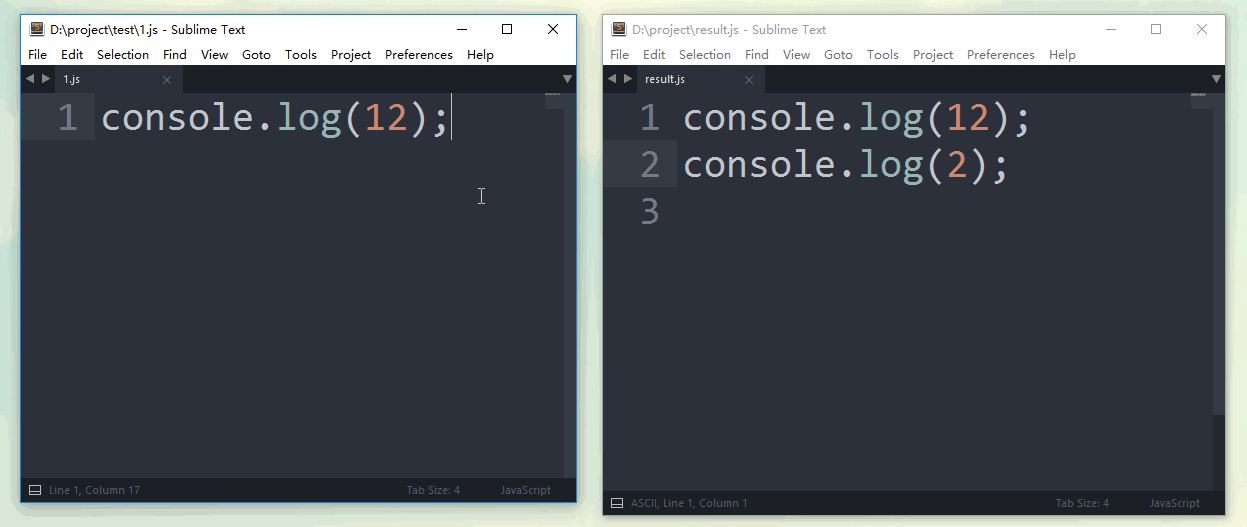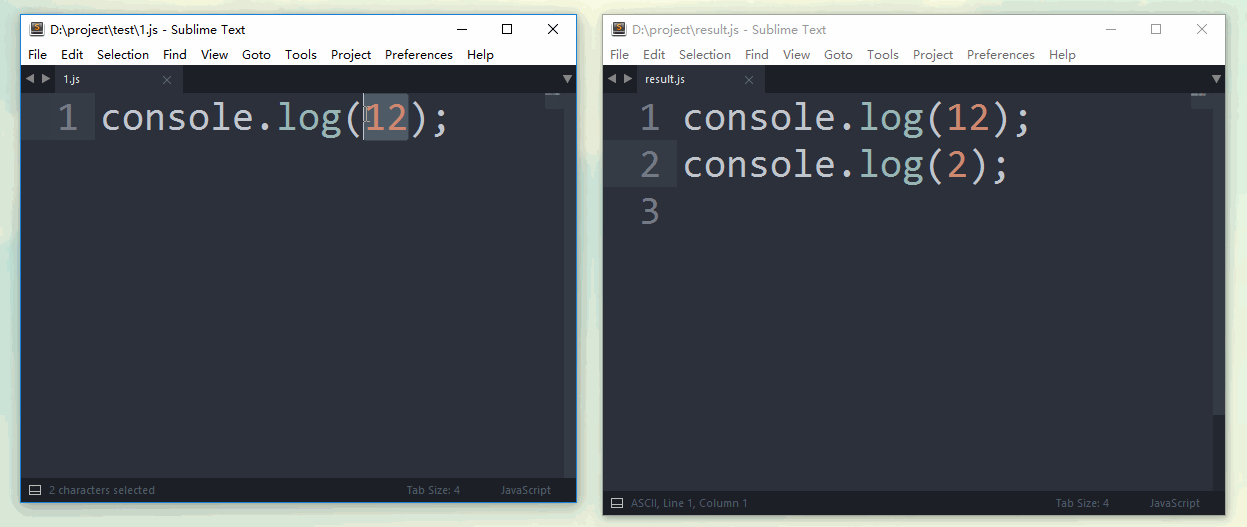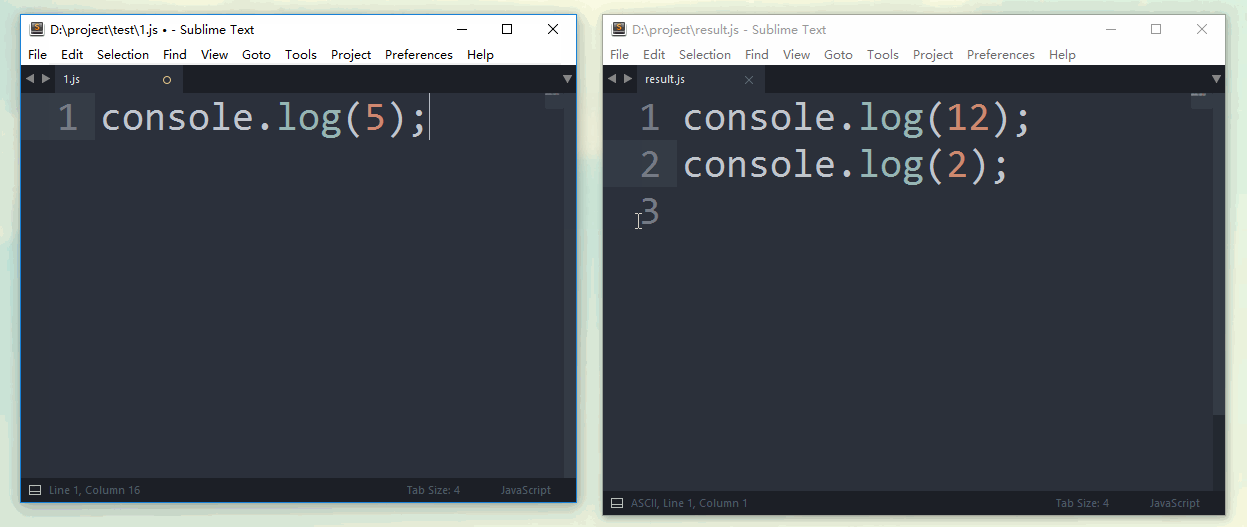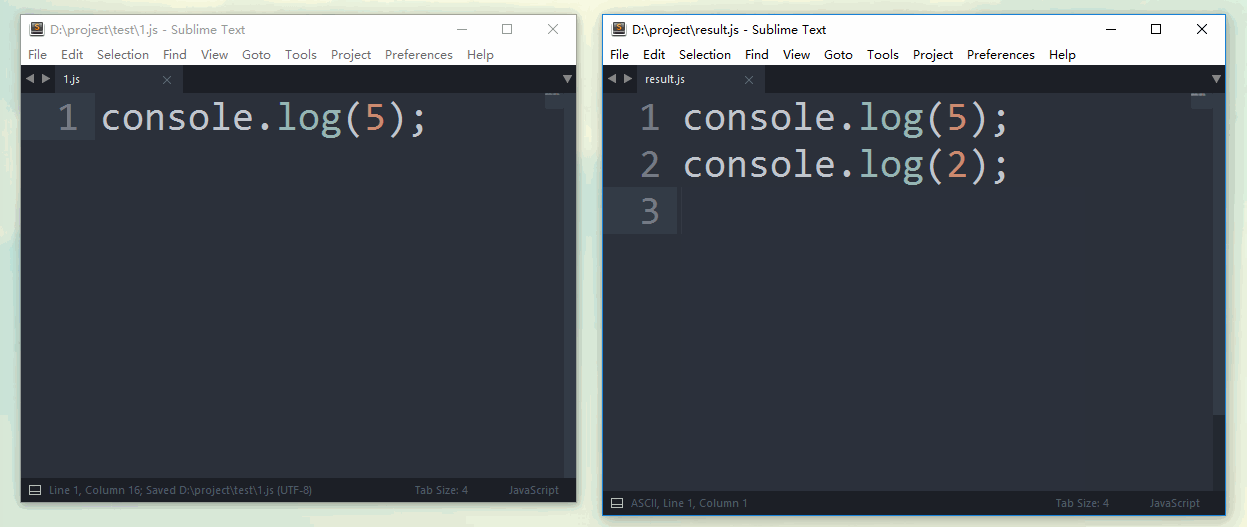
假设,目标是合并'test'目录下的所有js文件。'test'目录结构如下所示,包含1.js,以及js文件夹内的2.js
1.js
js
2.js其中,1.js与2.js的内容如下
//1.js console.log(1); //2.js console.log(2);
在合并这两个文件之前,首先需要实现一个目录遍历函数来遍历'test'目录,根据nodejs之文件操作博客中的目录遍历章节,可得到如下代码
function travel(dir, callback) {
fs.readdirSync(dir).forEach(function (file) {
var pathname = path.join(dir, file);
if (fs.statSync(pathname).isDirectory()) {
travel(pathname, callback);
} else {
callback(pathname);
}
});
}文件合并的逻辑如下
var fs = require('fs');
var path = require('path');var path = require('path');
var filedir = './test';
fs.watch(filedir, function(ev, file) {
//用于存放所有的js文件
var arr = [];
//将每一个js文件的路径存到arr数组中
function travel(dir) {
fs.readdirSync(dir).forEach(function (file) {
var pathname = path.join(dir, file);
if (fs.statSync(pathname).isDirectory()) {
travel(pathname);
} else {
arr.push(pathname);
}
});
}
//只要有一个文件发生了变化,我们就需要对这个文件夹下的所有文件进行读取,然后合并
travel(filedir);
//读取数组arr中的文件内容,并合并
function concat(arr){
var content = '';
arr.forEach(function(item) {
var c = fs.readFileSync(item);
content += c.toString() + '\n';
});
fs.writeFile('./result.js', content);
}
concat(arr);
});这样,当1.js文件内容发生改变时,合并后的结果文件result.js会立刻生效,并重新合并为最新内容